k8s 基础入门
常用命令
Kubectl 常用命令
| 命令 | 说明 |
|---|---|
kubectl get node | 查看当前的 node 状态 |
kubectl get pod -A | 查看所有的 pod 状态 |
kubectl get pod -A -o wide | 查看所有pod 的状态的详细信息(可以看到在那个机器上) |
source <(kubectl completion bash) | kubectl 命令自动补全 |
kubectl expose pod [pod name] --port 8000 | 暴露80的端口到8000 |
kubectl get services | 列出所有的服务 |
kubectl delete service [services name] | 删除服务 |
kubectl explain [命令] | 查询命令的文档 |
kubectl apply -f [yaml] | 通过yaml 创建相关资源 |
kubectl config get-contexts | 获取k8s 集群的上下文 |
kubectl config set-context --current --namespace=[namespace] | 设置默认的 namespace |
kubeadm 常用命令
| 命令 | 说明 |
|---|---|
kubeadm token list | 获取加入集群的 token |
openssl x509 -in /etc/kubernetes/pki/ca.crt -pubkey -noout | openssl pkey -pubin -outform DER | openssl dgst -sha256 | 获取加入集群的 discovery-token-ca-cert-hash |
Vagrant 常用命令
| 命令 | 说明 |
|---|---|
vagrant box list | 查看目前已有的box |
vagrant box add | 新增加一个box |
vagrant box remove | 删除指定的box |
vagrant init | 初始化配置vagrantfile |
vagrant up | 启动虚拟机 |
vagrant ssh [pc name] | ssh登录虚拟机 |
vagrant suspend | 挂起虚拟机 |
vagrant reload | 重启虚拟机 |
vagrant halt | 关闭虚拟机 |
vagrant status | 查看虚拟机状态 |
vagrant destroy | 删除虚拟机 |
环境配置
当我们需要一个简单的 K8S 集群, 需要使用如下工具
kubeadmk8s 管理工具vagrant虚拟机管理器VirtualBox虚拟化driver
创建虚拟机
$ git clone https://github.com/xiaopeng163/learn-k8s-from-scratch
$ cd learn-k8s-from-scratch/lab/kubeadm-3-nodes
$ vagrant up
$ vagrant status
# Current machine states:
# k8s-master running (virtualbox)
# k8s-worker1 running (virtualbox)
# k8s-worker2 running (virtualbox)
# This environment represents multiple VMs. The VMs are all listed
# above with their current state. For more information about a specific
# VM, run `vagrant status NAME`.master 初始化
拉取镜像
$ vagrant ssh [machine name]
# 拉取镜像 可做可不做
$ sudo kubeadm config images pull
# I0601 05:57:31.644809 4849 version.go:256] remote version is much newer: v1.30.1; falling back to: # stable-1.29
# [config/images] Pulled registry.k8s.io/kube-apiserver:v1.29.5
# [config/images] Pulled registry.k8s.io/kube-controller-manager:v1.29.5
# [config/images] Pulled registry.k8s.io/kube-scheduler:v1.29.5
# [config/images] Pulled registry.k8s.io/kube-proxy:v1.29.5
# [config/images] Pulled registry.k8s.io/coredns/coredns:v1.11.1
# [config/images] Pulled registry.k8s.io/pause:3.9
# [config/images] Pulled registry.k8s.io/etcd:3.5.10-0初始化 Kebeadm
-
--apiserver-advertise-address这个地址是本地用于和其他节点通信的IP地址(master 的ip) -
--pod-network-cidrpod network 地址空间(不要跟本地的地址空间有冲突) -
初始化, 成功后会给出需要继续执行的代码
$ sudo kubeadm init --apiserver-advertise-address=192.168.56.10 --pod-network-cidr=10.244.0.0/16 # Your Kubernetes control-plane has initialized successfully! # To start using your cluster, you need to run the following as a regular user: # mkdir -p $HOME/.kube # sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config # sudo chown $(id -u):$(id -g) $HOME/.kube/config # Alternatively, if you are the root user, you can run: # export KUBECONFIG=/etc/kubernetes/admin.conf # You should now deploy a pod network to the cluster. # Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at: # https://kubernetes.io/docs/concepts/cluster-administration/addons/ # Then you can join any number of worker nodes by running the following on each as root: # kubeadm join 192.168.56.10:6443 --token 3twkp1.92vffsjjkuwg6mi9 \ # --discovery-token-ca-cert-hash sha256:8b506bd765bc638bff50e8c773be575f54beba3fccbe9e9b4f2e0a4ad4cd598a -
保存
.kube配置:# 保存一些基本的配置给 kubectl mkdir -p $HOME/.kube sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config sudo chown $(id -u):$(id -g) $HOME/.kube/config # 检查状态: kubectl get nodes kubectl get pods -A -
部署 Pod network 方案, 这里我们选择 flannel (opens in a new tab) 在 kube-flannel的容器args里,确保有iface=enp0s8, 其中enp0s8是我们的–apiserver-advertise-address=192.168.56.10 接口名
# flannel 配置里我们需要设置 Network 地址,需要与 --pod-network-cidr 地址一致 net-conf.json: | { "Network": "10.244.0.0/16", "Backend": { "Type": "vxlan" } } # ... - name: kube-flannel image: docker.io/flannel/flannel:v0.24.2 command: - /opt/bin/flanneld args: - --ip-masq - --kube-subnet-mgr - --iface=enp0s8 # 这里与 ip a 命令查看的接口名一样应用网络方案配置
vagrant@k8s-master:~$ kubectl apply -f flannel.yml # namespace/kube-flannel created # clusterrole.rbac.authorization.k8s.io/flannel created # clusterrolebinding.rbac.authorization.k8s.io/flannel created # serviceaccount/flannel created # configmap/kube-flannel-cfg created # daemonset.apps/kube-flannel-ds created # 此时 node 的状态应该发生了改变 vagrant@k8s-master:~$ kubectl get node # NAME STATUS ROLES AGE VERSION # k8s-master Ready control-plane 38m v1.29.2增加集群 Worker
此时master 节点和 worker 还不在一个集群中:
vagrant@k8s-master:~$ kubectl get node # NAME STATUS ROLES AGE VERSION # k8s-master Ready control-plane 38m v1.29.2初始化完成的时候,kubeadm 给了我们一个命令行,用来增加 worker,需要在 worker 中去执行这个命令,使 worker 加入集群
vagrant@k8s-worker1:~$ sudo kubeadm join 192.168.56.10:6443 --token 3twkp1.92vffsjjkuwg6mi9 --discovery-token-ca-cert-hash sha256:8b506bd765bc638bff50e8c773be575f54beba3fccbe9e9b4f2e0a4ad4cd598a # [preflight] Running pre-flight checks # [preflight] Reading configuration from the cluster... # [preflight] FYI: You can look at this config file with 'kubectl -n kube-system get cm kubeadm-config -o yaml' # [kubelet-start] Writing kubelet configuration to file "/var/lib/kubelet/config.yaml" # [kubelet-start] Writing kubelet environment file with flags to file "/var/lib/kubelet/kubeadm-flags.env" # [kubelet-start] Starting the kubelet # [kubelet-start] Waiting for the kubelet to perform the TLS Bootstrap... # This node has joined the cluster: # * Certificate signing request was sent to apiserver and a response was received. # * The Kubelet was informed of the new secure connection details. # Run 'kubectl get nodes' on the control-plane to see this node join the cluster. vagrant@k8s-master:~$ kubectl get node # NAME STATUS ROLES AGE VERSION # k8s-master Ready control-plane 50m v1.29.2 # k8s-worker1 Ready <none> 77s v1.29.2
INTERNAL-IP 问题
当使用 vagrant 创建的集群时候,node 的 INTERNAL-IP 是完全一样的
vagrant@k8s-master:~$ kubectl get node -o wide
# NAME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME
# k8s-master Ready control-plane 138m v1.29.2 10.0.2.15 <none> Ubuntu 20.04.6 LTS 5.4.0-182-generic containerd://1.6.32
# k8s-worker1 Ready <none> 88m v1.29.2 10.0.2.15 <none> Ubuntu 20.04.6 LTS 5.4.0-182-generic containerd://1.6.32
# k8s-worker2 Ready <none> 85m v1.29.2 10.0.2.15 <none> Ubuntu 20.04.6 LTS 5.4.0-182-generic containerd://1.6.32编辑 kubeadm 配置文件
vagrant@k8s-master:~$ sudo vim /var/lib/kubelet/kubeadm-flags.env
# KUBELET_KUBEADM_ARGS="--container-runtime-endpoint=unix:///var/run/containerd/containerd.sock --pod-# infra-container-image=registry.k8s.io/pause:3.9"
#KUBELET_EXTRA_ARGS="--node-ip=192.168.56.10" 新增这一行重启服务
vagrant@k8s-master:~$ sudo systemctl daemon-reload
vagrant@k8s-master:~$ sudo systemctl restart kubelet
vagrant@k8s-master:~$ kubectl get node -o wide
# NAME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME
# k8s-master Ready control-plane 146m v1.29.2 192.168.56.10 <none> Ubuntu 20.04.6 LTS 5.4.0-182-generic containerd://1.6.32
# k8s-worker1 Ready <none> 97m v1.29.2 10.0.2.15 <none> Ubuntu 20.04.6 LTS 5.4.0-182-generic containerd://1.6.32
# k8s-worker2 Ready <none> 94m v1.29.2 10.0.2.15 <none> Ubuntu 20.04.6 LTS 5.4.0-182-generic containerd://1.6.32此时可以看到 master 节点已经修改过来了。
所有的work 都需要这样子修改,但是 ip 是不同的
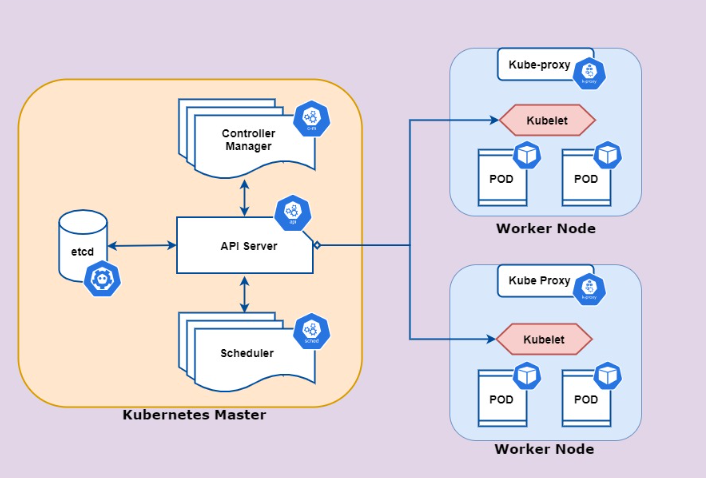
K8S API Server
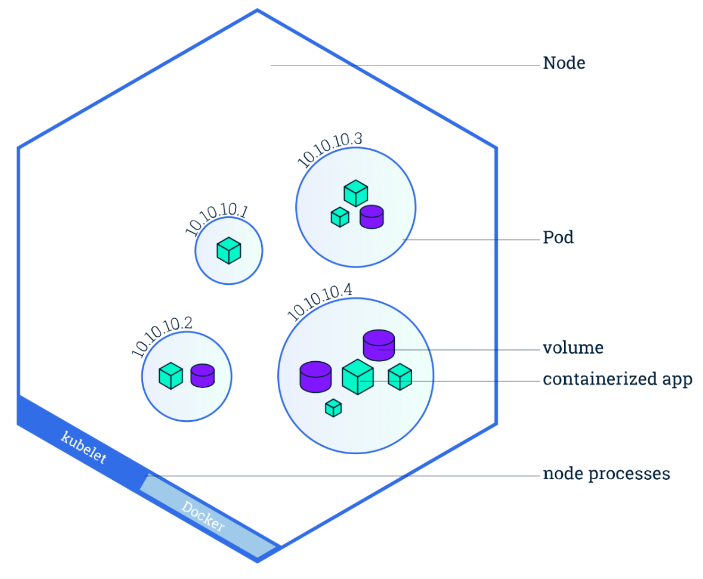
Pod
- 一组一个或多个应用程序容器及其共享资源(例如卷)
- Pod 共享与网络名称空间相同的名称空间(具有相同的 IP 地址。)
- Pod是k8s里最小的调度单位。
通过命令行创建Pod
| 命令 | 例子 | 说明 |
|---|---|---|
| kubectl run [ pod name ] --image=[ image name ] | kubectl run web --image=nginx | 在k8s上用nginx的image创建一个pod |
| kubectl run [pod name] –image=[ image name] --command -- [ cmd ] [ arg1 ] … [ argN ] | $ kubectl run client --image=busybox --command -- bin/sh -c "sleep 100000" | 在k8s上用busybox 的image创建一个pod并执行命令 |
yaml 声明式创建
以下yaml文件是定义一个pod所需的最少字段 (nginx.yml)
apiVersion: v1
kind: Pod
metadata:
name: web
spec:
containers:
- name: nginx-container
image: nginx:latest运行一个命令, sh -c “sleep 1000000”
apiVersion: v1
kind: Pod
metadata:
name: client
spec:
containers:
- name: client
image: busybox
command: #定义一个需要运行的命令
- sh
- -c
- "sleep 1000000"多个Container Pod
apiVersion: v1
kind: Pod
metadata:
name: my-pod
spec:
containers:
- name: nginx
image: nginx
- name: client
image: busybox
command:
- sh
- -c
- "sleep 1000000"模拟创建
Server-side
和正常情况一样处理客户端发送过来的请求,但是并不会把Object状态持久化存储到storage中
$ kubectl apply -f nginx.yml --dry-run=serverClient-side
- 把要操作的Object通过标准输出stdout输出到terminal
- 验证manifest的语法
- 可以用于生成语法正确的Yaml manifest
$ kubectl apply -f nginx.yml --dry-run=client
$ kubectl run web --image=nginx --dry-run=client -o yaml
$ kubectl run web --image=nginx --dry-run=client -o yaml > nginx.ymlPod 的基本操作
| 命令 | 说明 |
|---|---|
| kubectl get pods | 获取 pod 列表 |
| kubectl get pods -o wide --show-labels | 获取 pod 的列表的详细信息,并显示label |
| kubectl get pod [ pod name ] -o wide | 获取指定 pod 的信息 |
| kubectl get pod -o wide | 获取pod的详细信息 |
| kubectl get pod [ pod name ] -o wide | 获取指定pod的详细信息 |
| kubectl describe pod [ pod name ] | 获取指定 pod 的详细信息 |
| kubectl delete pod [ pod name ] | 删除指定的 pod |
| kubectl apply -f [ pod yaml ] | 通过 yaml 创建 pod |
| kubectl run [ pod name ]--image=[ image name ] --namespace=[ namespace ] | 创建pod 到指定的命名空间 |
vagrant@k8s-master:~$ kubectl describe pod web1
Name: web1
Namespace: default
Priority: 0
Service Account: default
Node: k8s-worker2/192.168.56.12
Start Time: Mon, 08 Jul 2024 15:41:25 +0000
Labels: run=web1
Annotations: <none>
Status: Running
IP: 10.244.2.2
IPs:
IP: 10.244.2.2
Containers:
web1:
Container ID: containerd://2d7fba804ae7f6d1dad93ae71d0ee0ebb1afe5c7fbc4280405fb7f779a4a3ae3
Image: nginx
Image ID: docker.io/library/nginx@sha256:67682bda769fae1ccf5183192b8daf37b64cae99c6c3302650f6f8bf5f0f95df
Port: <none>
Host Port: <none>
State: Running
Started: Mon, 08 Jul 2024 15:42:00 +0000
Ready: True
Restart Count: 0
Environment: <none>
Mounts:
/var/run/secrets/kubernetes.io/serviceaccount from kube-api-access-c5dr4 (ro)
Conditions:
Type Status
PodReadyToStartContainers True
Initialized True
Ready True
ContainersReady True
PodScheduled True
Volumes:
kube-api-access-c5dr4:
Type: Projected (a volume that contains injected data from multiple sources)
TokenExpirationSeconds: 3607
ConfigMapName: kube-root-ca.crt
ConfigMapOptional: <nil>
DownwardAPI: true
QoS Class: BestEffort
Node-Selectors: <none>
Tolerations: node.kubernetes.io/not-ready:NoExecute op=Exists for 300s
node.kubernetes.io/unreachable:NoExecute op=Exists for 300s
Events: # 事件信息 如果有错误这里也看得到
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Pulling 8m2s kubelet Pulling image "nginx"
Normal Scheduled 7m50s default-scheduler Successfully assigned default/web1 to k8s-worker2
Normal Pulled 7m28s kubelet Successfully pulled image "nginx" in 34.27s (34.27s including waiting)
Normal Created 7m28s kubelet Created container web1
Normal Started 7m28s kubelet Started container web1进入容器执行命令
| 命令 | 说明 |
|---|---|
| kubectl exec [ pod name ] -- [ cmd ] | 对一个指定的 pod 执行命令 【pod 中只有单个container 情况,如果是含有多个container 会默认使用第一个来执行命令】 |
| kubectl exec [ pod name ] -it -- sh | 进入交互式的环境【pod 中只有单个container 情况,如果是含有多个container 会默认使用第一个来执行命令】 |
| kubectl exec [ pod name ] -c [ container name ] -- date | 对一个指定的含有多个 container 的 pod 执行命令 |
| kubectl exec [ pod name ] -c [ container name ] -it -- sh | 对一个指定的含有多个 container 的 pod 指定对应的 container 来进入交互式的环境 |
API level log
获取kubectl操作更详细的log, API level( 通过 -v 指定)
$ kubectl get pod [ pod-name ] -v 6 # 或者 7,8,9 不同的level,数值越大,得到的信息越详细--watch 持续监听kubectl操作,API level
$ kubectl get pods <pod-name> --watch -v 6Namespaces 命名空间
namespaces 基本操作
| 命令 | 说明 |
|---|---|
| kubectl get namespaces | 获取所有的 namespace |
| kubectl get pods | 获取default 命名空间下的所有 pod |
| kubectl get pods --namespace [ namespace ] | 获取指定命名空间下的所有 pod |
| kubectl get pods [ pod name ] --namespace=[ namespace ] | 获取指定命名空间下的 [ pod name ] 的信息 |
| kubectl get pods -A | 获取所有命名空间下的pod |
| kubectl describe namespaces [ namespace ] | 查看相关命名空间的详细信息 |
| kubectl delete namespace [ namespace ] | 删除指定的命名空间 |
| kubectl create namespace [ namespace ] | 创建指定的命名空间 |
相关示例
# create namespace with yaml
vagrant@k8s-master:~$ kubectl create namespace demo --dry-run=client -o yaml > demo.yaml
vagrant@k8s-master:~$ more demo.yaml
apiVersion: v1
kind: Namespace
metadata:
creationTimestamp: null
name: demo
spec: {}
status: {}
vagrant@k8s-master:~$ kubectl apply -f demo.yaml
namespace/demo created
# 创建pod到指定的命名空间的yaml 格式:
vagrant@k8s-master:~$ kubectl run web --image=nginx --namespace=demo --dry-run=client -o yaml
apiVersion: v1
kind: Pod
metadata:
creationTimestamp: null
labels:
run: web
name: web
namespace: demo
spec:
containers:
- image: nginx
name: web
resources: {}
dnsPolicy: ClusterFirst
restartPolicy: Always
status: {}
# 查看当前的 k8s 上下文
vagrant@k8s-master:~$ kubectl config get-contexts
CURRENT NAME CLUSTER AUTHINFO NAMESPACE
* kubernetes-admin@kubernetes kubernetes kubernetes-admin
vagrant@k8s-master:~$
# 设置默认的 namespace
vagrant@k8s-master:~$ kubectl config set-context --current --namespace=demo
Context "kubernetes-admin@kubernetes" modified.
vagrant@k8s-master:~$
vagrant@k8s-master:~$ kubectl config get-contexts
CURRENT NAME CLUSTER AUTHINFO NAMESPACE
* kubernetes-admin@kubernetes kubernetes kubernetes-admin demo
Static Pod
参考 https://kubernetes.io/docs/tasks/configure-pod-container/static-pod/ (opens in a new tab)
- 由 Node 上的 kubelet 管理
- 静态 Pod 配置,kubelet 配置中的
staticPodPath,默认为/etc/kubernetes/manifests(只要放置了 yaml 文件,k8s 会默认自动创建) - kubelet 配置文件:
/var/lib/kubelet/config.yaml - pod可以通过API服务器“看到”,但不能被API服务器管理
init containers
init container 我自以为作为初始化服务,主要作用:
- 初始化
- 处理依赖,控制启动
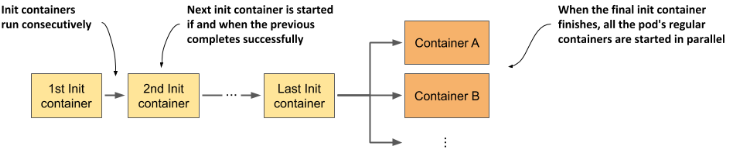
apiVersion: v1
kind: Pod
metadata:
name: pod-with-init-containers
spec:
initContainers:
- name: init-service # 首先初始化它
image: busybox
command: ["sh", "-c", "echo waiting for sercice; sleep 4"]
- name: init-database # 然后是它
image: busybox
command: ["sh", "-c", "echo waiting for database; sleep 4"]
containers: # 最后才是这个本体服务
- name: app-container
image: nginxPod 的生命周期
参考 https://kubernetes.io/docs/concepts/workloads/pods/pod-lifecycle/ (opens in a new tab)
Pod Phase
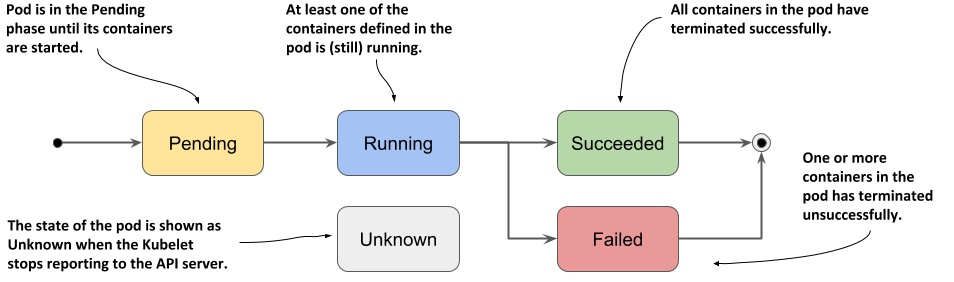
Container state
- waiting
- Running
- Termination
- Process is terminated/crashed
- Pod is deleted
- Node failure or maintenance
- Evicteed due to lack of resources
Stopping/Terminating Pods
kubectl delete pod [ pod name ] 当执行删除的时候,
- API server会设置一个timer(grace period Timer),默认是30秒
- 同时pod状态改成Terminating
- Pod所在node上的kubelet收到命令,会给Pod里的container发送SIGTERM信号,然后等等container退出
- 如果container在timer到时之前退出了,那么pod信息同时会被API server从存储中删除
- 如果container没有在timer到时之前退出,则kubelet会发送SIGKILL信息到pod里的容器,强制杀死容器, 最后API server更新存储etcd
grace period timer是可以修改的
$ kubectl delete pod [ pod name ] --grace-period=[ seconds ]apiVersion: v1
kind: Pod
metadata:
name: web
spec:
terminationGracePeriodSeconds: 10
containers:
- image: nginx
name: web或者强制删除 pod
$ kubectl delete pod [ pod name ] --grace-period=0 --forcePersistency of Pod 持久化
Pod本身不会重新自动部署,它不会重启动,只有可能创建一个新的
配置持久化:
- Pod Manifests, secrets and ConfigMaps (pod 的yaml 创建文件,k8s 的secrets 、ConfigMaps )
- environment variables (环境变量)
数据持久化
- PersistentVolume
- PersistentVolumeClaim
Container Restart Policy 容器的重启策略
重启策略有三种:
- Always (container 自动退出了就自动重启)
- OnFailure (container 遇到了错误自动重启)
- Never (不重启)
vagrant@k8s-master:~$ kubectl run web --image nginx --dry-run=client -o yaml
apiVersion: v1
kind: Pod
metadata:
creationTimestamp: null
labels:
run: web
name: web
spec:
containers:
- image: nginx
name: web
resources: {}
dnsPolicy: ClusterFirst
restartPolicy: Always
status: {}Controller and Deployment
Controller Manager
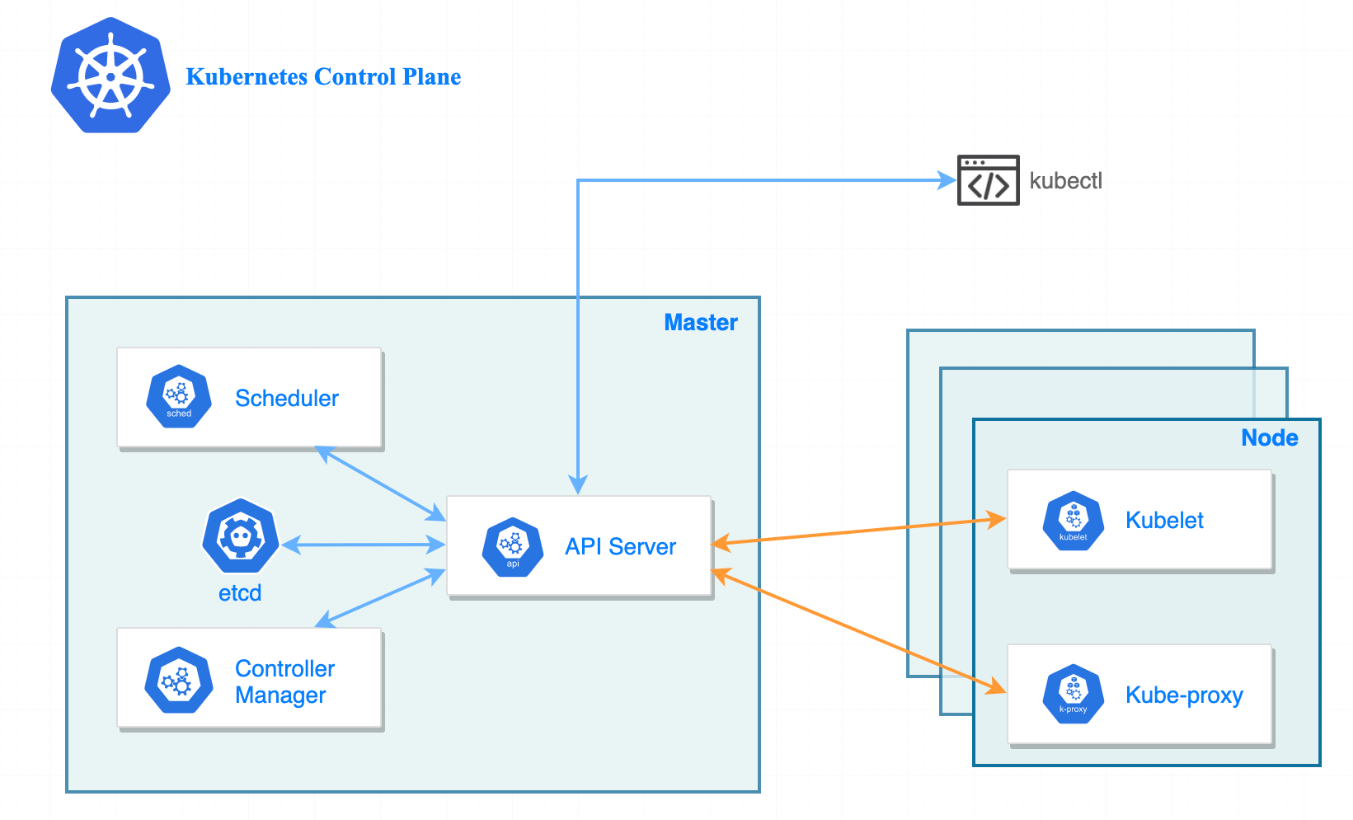
controller 是用来追踪资源的,这些资源都有一个期望的状态(desired state), controller回去监控对应的资源的状态,确保资源处在期望的状态,如果不处在期望的状态,采取对应的措施
Controllers 分类:
-
Pod Controllers
-
ReplicaSet
-
Deployment
-
DaemonSet
-
StatefulSet
-
Job
-
CronJob
-
-
Other Controllers
-
Node
-
Service
-
Endpoint
-
controller Manager 是管理很多 controller 的。
controller Manager 分为两类:
- kube controller Manager
- cloud controller Manager
Labels 标签
- Controllers and Services match pods using Selectors
- Pod Scheduling, scheduling to specific Node
查看label
| 命令 | 说明 |
|---|---|
| kubectl get pods --show-labels | 获取默认命名空间下的 pods 的信息,并带上标签信息 |
kubectl describe pod [ pod name ] | 获取指定pod 的详细信息,会带有标签信息 |
vagrant@k8s-master:~$ kubectl get pods --show-labels
NAME READY STATUS RESTARTS AGE LABELS
nginx-pod-1 1/1 Running 0 24s app=v1,tier=PROD
nginx-pod-2 1/1 Running 0 24s app=v1,tier=ACC
nginx-pod-3 1/1 Running 0 24s app=v1,tier=TEST添加和修改标签
- 通过cli 来进行
- 通过 yaml 文件来设置
apiVersion: v1
kind: Pod
metadata:
name: nginx-pod-1
labels:
app: v1
tier: PROD
spec:
containers:
- name: nginx
image: nginx
---
apiVersion: v1
kind: Pod
metadata:
name: nginx-pod-2
labels:
app: v1
tier: ACC
spec:
containers:
- name: nginx
image: nginx
---
apiVersion: v1
kind: Pod
metadata:
name: nginx-pod-3
labels:
app: v1
tier: TEST
spec:
containers:
- name: nginx
image: nginx| 命令 | 说明 |
|---|---|
kubectl label pod [pod name] [ KEY]= [VALUE] | 为指定的pod设置标签 |
kubectl label pod [pod name] [ KEY]= [VALUE] --overwrite | 修改指定pod 的标签 |
kubectl label pod [pod name] [ KEY]- | 删除标签 |
# 设置标签
vagrant@k8s-master:~$ kubectl label pod nginx-pod-1 color=red
pod/nginx-pod-1 labeled
vagrant@k8s-master:~$
vagrant@k8s-master:~$
vagrant@k8s-master:~$ kubectl get pods --show-labels
NAME READY STATUS RESTARTS AGE LABELS
nginx-pod-1 1/1 Terminating 0 6m13s app=v1,color=red,tier=PROD
nginx-pod-2 1/1 Terminating 0 6m13s app=v1,tier=ACC
nginx-pod-3 1/1 Terminating 0 6m13s app=v1,tier=TEST
# 修改标签
vagrant@k8s-master:~$ kubectl label pod nginx-pod-1 color=blue --overwrite
pod/nginx-pod-1 labeled
vagrant@k8s-master:~$ kubectl get pods --show-labels
NAME READY STATUS RESTARTS AGE LABELS
nginx-pod-1 1/1 Terminating 0 17m app=v1,color=blue,tier=PROD
nginx-pod-2 1/1 Terminating 0 17m app=v1,tier=ACC
nginx-pod-3 1/1 Terminating 0 17m app=v1,tier=TEST
# 删除标签
vagrant@k8s-master:~$ kubectl label pod nginx-pod-1 color-
pod/nginx-pod-1 unlabeled
vagrant@k8s-master:~$ kubectl get pods --show-labels
NAME READY STATUS RESTARTS AGE LABELS
nginx-pod-1 1/1 Terminating 0 20m app=v1,tier=PROD
nginx-pod-2 1/1 Terminating 0 20m app=v1,tier=ACC
nginx-pod-3 1/1 Terminating 0 20m app=v1,tier=TEST查询 label
| 命令 | 说明 |
|---|---|
kubectl get pods --selector [ KEY]= [VALUE] | 单个查询 [ KEY]= [VALUE] 的 pod |
kubectl get pods -l " [KEY] in ([ value ], [ value ])" | 批量查询 key 的值包含 value |
kubectl get pods -l " [KEY] notin ([ value ], [ value ])" | 批量查询 key 的值不包含 value |
# 单次查询
vagrant@k8s-master:~$ kubectl get pods --selector tier=PROD --show-labels
NAME READY STATUS RESTARTS AGE LABELS
nginx-pod-1 1/1 Terminating 0 34m app=v1,tier=PROD
# 批量查询
vagrant@k8s-master:~$ kubectl get pods -l "tier in (PROD, ACC)" --show-labels
NAME READY STATUS RESTARTS AGE LABELS
nginx-pod-1 1/1 Terminating 0 33m app=v1,tier=PROD
nginx-pod-2 1/1 Terminating 0 33m app=v1,tier=ACC
vagrant@k8s-master:~$ kubectl get pods -l "tier notin (PROD, ACC)" --show-labels
NAME READY STATUS RESTARTS AGE LABELS
nginx-pod-3 1/1 Terminating 0 35m app=v1,tier=TESTDeployment (opens in a new tab)
一个部署中描述了一个期望的状态,部署控制器会以一个可控的速率将实际状态改变到期望状态。可以定义部署来创建新的副本集,或者移除现有的部署并用新的部署接管它们的所有资源。
| 命令 | 说明 |
|---|---|
| kubectl get deployments.apps | 获取所有的 `deployments |
kubectl edit deployments.apps [ deployments name] | 编辑对应的 deployments 的配置 |
kubectl scale deployments [ deployments name] --replicas [ num ] | 将对应的deployments进行水平拓展 |
deployment 的创建
| 命令 | 说明 |
|---|---|
kubectl create deployment web --image=[ image name] | 创建一个deployment |
通过yaml 创建
# kubectl create deployment web --image=nginx:1.14.2 --dry-run=client -o yaml
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: web
name: web
spec:
replicas: 1
selector:
matchLabels:
app: web
template:
metadata:
labels:
app: web
spec:
containers:
- image: nginx:1.14.2
name: nginx# 生成配置yaml
vagrant@k8s-master:~$ kubectl create deployment web --image=nginx:1.14.2 --dry-run=client -o yaml > web.yaml
vagrant@k8s-master:~$
# 创建 deploments
vagrant@k8s-master:~$ kubectl apply -f web.yaml
deployment.apps/web created
# 获取所有的 deployments.apps
vagrant@k8s-master:~$ kubectl get deployments.apps
NAME READY UP-TO-DATE AVAILABLE AGE
web 1/1 1 1 26s
# 获取所有的 replicasets.apps(相同的命名,控制着deployments.apps)
# 当对应的 deployments.apps 被删除的时候,这个replicasets.apps也会被删除
vagrant@k8s-master:~$ kubectl get replicasets.apps
NAME DESIRED CURRENT READY AGE
web-685666b9cc 1 1 1 59sPod Failures
当我们的 deployment pod 失败的时候,或者被我们强行删除的时候, ReplicaSet 会立马帮我们重启、或者创建对应的pod, ReplicaSet 其实是通过 labels来判断对应app 的数量,app这个tag的值是对应的deployment 名字,当我们的这个pod标签改变的时候, 会立马帮我们重启、或者创建对应的pod,当出现多余的pod 的时候,会删除
#
vagrant@k8s-master:~$ kubectl get pods --show-labels
NAME READY STATUS RESTARTS AGE LABELS
web-76fd95c67-k6b8t 1/1 Running 0 19m app=web,pod-template-hash=76fd95c67
web-76fd95c67-nnpxp 1/1 Running 0 19m app=web,pod-template-hash=76fd95c67
web-76fd95c67-vgzhc 1/1 Running 0 20m app=web,pod-template-hash=76fd95c67Node Failures
- 暂时性失联(网络不通之类的)
- 永久性失联
- kube-contorller-manager 有一个timeout的设置,pod-eviction-timeout (默认5min) Node如果失联超过5分钟,便视为永久性失联,就会触发在其上运行的Pod的终止和重建(在其他节点上重建)。
Update Deployment (opens in a new tab)
在Deployment 中,默认是RollingUpdate 模式(不是一次性的把旧版本杀死,而是诸葛替换)
$ kubectl set image deployment/web nginx=nginx:1.14.2 # 更新web 这个 deployment 的镜像为 1.14.2Max Unavailable
是一个可选字段,用于指定在更新过程中可以不可用的最大 Pod 数量。该值可以是绝对数字(例如,5)或所需 Pod 的百分比(例如,10%)。绝对数字是根据百分比向下舍入计算得出的。如果 .spec.strategy.rollingUpdate.maxSurge 为 0,则该值不能为 0。默认值为 25%。
例如,当此值设置为 30% 时,当滚动更新开始时,旧的 ReplicaSet 可以立即缩减到所需 Pod 的 70%。一旦新的 Pod 准备就绪,旧的 ReplicaSet 可以进一步缩减,然后放大新的 ReplicaSet,确保在更新期间始终可用的 Pod 总数至少是所需 Pod 的 70%。
Max Surge
是一个可选字段,用于指定在所需数量的 Pod 上可以创建的最大 Pod 数量。该值可以是绝对数字(例如,5)或所需 Pod 的百分比(例如,10%)。如果 MaxUnavailable 为 0,则该值不能为 0。绝对数字是根据百分比四舍五入计算得出的。默认值为 25%。
例如,当此值设置为 30% 时,当滚动更新开始时,新的 ReplicaSet 可以立即纵向扩展,使得新旧 Pod 的总数不超过所需 Pod 的 130%。一旦旧的 Pod 被杀死,新的 ReplicaSet 可以进一步扩展,确保在更新期间任何时间运行的 Pod 总数最多是所需 Pod 的 130%
Rolling Back
| 命令 | 说明 |
|---|---|
kubectl rollout history deployment [ deployment name ] | 查看对应的deployment name 的历史版本 |
kubectl rollout history deployment [ deployment name ] --revision [ num ] | 查看对应的deployment name 的指定历史版本 |
kubectl rollout undo deployment [ deployment name ] --to-revision [ num ] | 回滚对应的deployment name 的指定历史版本 |
kubectl rollout restart deployment [ deployment name ] | 回滚对应的deployment name (本质上是销毁重建,会增加历史版本) |
当我们更新一个deployment的时候,会有历史的版本存在:
# web 服务更新镜像后,存留了一个历史版本
vagrant@k8s-master:~$ kubectl get replicasets.apps -o wide
NAME DESIRED CURRENT READY AGE CONTAINERS IMAGES SELECTOR
web-76fd95c67 0 0 0 4h11m nginx nginx app=web,pod-template-hash=76fd95c67
web-85d7c4c487 3 3 3 12m nginx nginx:1.14.2 app=web,pod-template-hash=85d7c4c487DaemonSet
确保所有或者部分Kubernetes集群节点上运行一个pod。当有新节点加入时,pod也会运行在上面。
常见例子:
- kube-proxy 网络相关
- log collectors
- metric servers
- Resource monitoring agent
- storage daemons
| 命令 | 说明 |
|---|---|
| kubectl get daemonsets.apps | 获取所有的daemonsets |
语法
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: hello-ds
spec:
selector:
matchLabels:
app: hello-world
template:
metadata:
labels:
app: hello-world
spec:
containers:
- name: hello-world
image: nginx:1.14可以指定node
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: hello-ds
spec:
selector:
matchLabels:
app: hello-world
template:
metadata:
labels:
app: hello-world
spec:
nodeSelector:
node: hello-world # 这里指定了node
containers:
- name: hello-world
image: nginx:1.14Update Strategy
- RollingUpdate
- OnDelete
Job
| 命令 | 说明 |
|---|---|
| kubectl get jobs | 获取所有的jobs |
一次性运行的Pod,一般为执行某个命令或者脚本,执行结束后pod的生命随之结束
$ kubectl create job my-job --image=busybox -- sh -c "sleep 50"apiVersion: batch/v1
kind: Job
metadata:
name: my-job
spec:
template:
spec:
containers:
- name: my-job
image: busybox
command: ["sh", "-c", "sleep 50"]
restartPolicy: NeverCronJob (opens in a new tab)
| 命令 | 说明 |
|---|---|
| kubectl get cronjobs.batch | 获取所有的计划任务 |
| kubectl describe cronjobs.batch | 查看所有的计划任务执行信息 |
apiVersion: batch/v1
kind: CronJob
metadata:
name: hello
spec:
schedule: "*/1 * * * *"
jobTemplate:
spec:
template:
spec:
containers:
- name: hello
image: busybox:1.28
imagePullPolicy: IfNotPresent
command:
- /bin/sh
- -c
- date; echo Hello from the Kubernetes cluster
restartPolicy: OnFailure